At first, “MiniMax Week” was mostly confined to internal industry chatter. The central question: how many state-of-the-art benchmarks would MiniMax claim this time?
That changed when the videos surfaced online.
Cats—tabbys, calicos, tuxedos—began appearing in athletic dives across social media. Then came alpacas, pandas, and giraffes performing spins and backflips off ten-meter towers. What’s more, the bounce of the springboard and size of the splash varied depending on each animal’s weight. Just like in real life.

And that was when MiniMax found its “aha moment.”
The term originates from psychology and product design, referring to the instant when users suddenly grasp a product’s value, often with surprise or delight.
These moments tend to signal a turning point: the shift from incremental improvement to qualitative change. They often precede spikes in user adoption, or even industry-wide breakthroughs.
In the realm of artificial intelligence-generated video, the diving animals did more than entertain. They also crossed a threshold. For years, actions like diving, gymnastics, or complex multi-agent movement were considered video AI’s “Turing test.”
Such feats demand more than frame-by-frame visual continuity. Motion must follow the laws of gravity and inertia. The springboard must flex and rebound. The splash must correspond to the dive angle. Each frame must adhere to a plausible physical trajectory.
This level of realism was made possible by MiniMax’s new video model: Hailuo 02.
Compared with its predecessor, Hailuo 01, the new model reportedly triples the parameter count and delivers native 1080p resolution. It can generate ten seconds of high-definition content in one go, simulating fluid dynamics, modeling mirror effects, and capturing precise movements with striking fidelity.
On the Artificial Analysis Video Arena leaderboard, Hailuo 02 ranks second globally. It outperforms Google’s Veo 3 while operating at just one-ninth of its API cost.
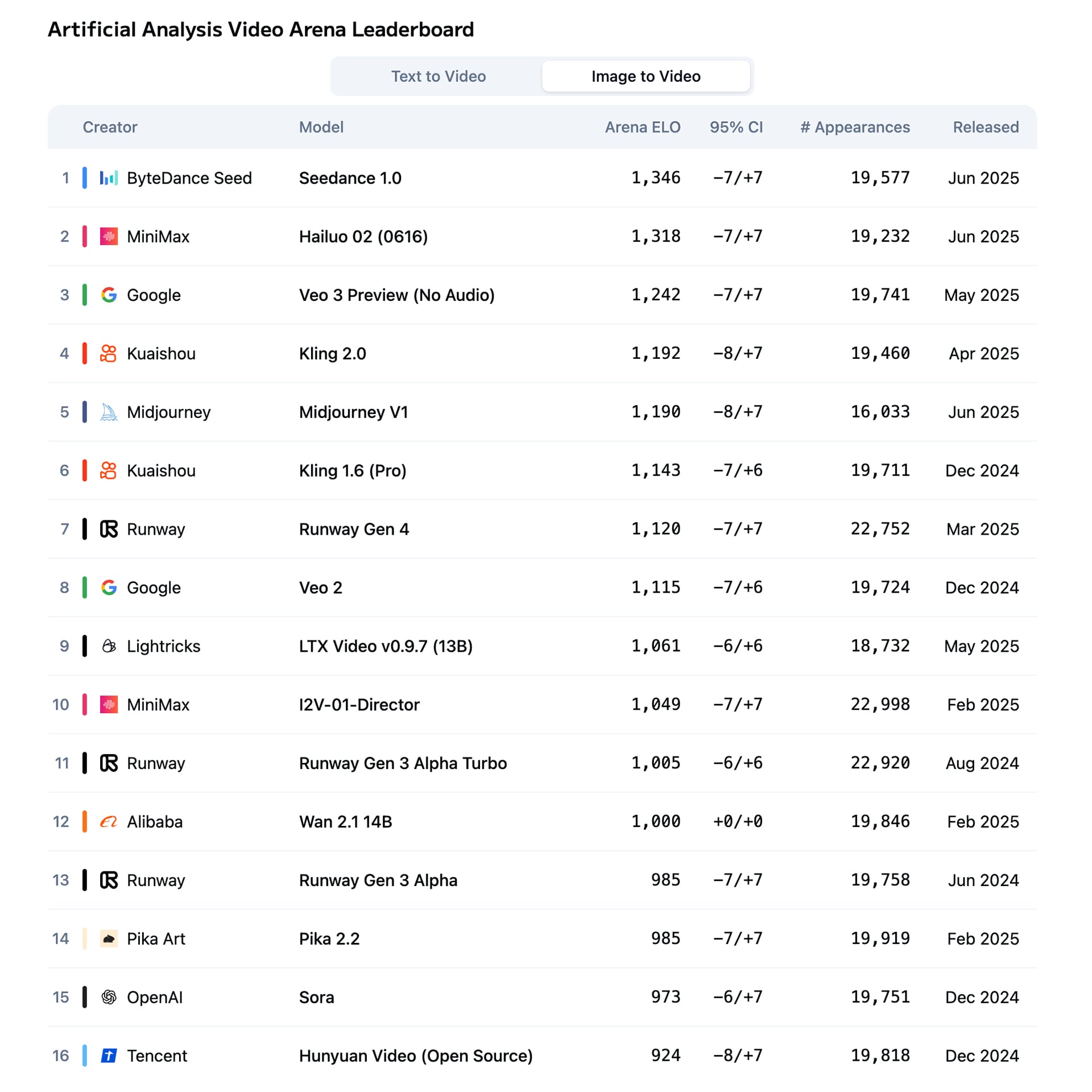
How? Two factors.
First, scaling law. Hailuo 02 was trained on four times more data and has three times the parameters of its predecessor, improving its ability to process complex instructions and physical environments.
Second, architecture. Hailuo 02 uses a noise-aware compute redistribution (NCR) design that dynamically allocates compute resources based on noise density. High-noise zones are compressed while low-noise areas receive more capacity for fine-grained detail. This results in 70% fewer high-bandwidth memory reads and writes, and a 2.5 times improvement in training and inference efficiency.
This focus on optimizing effort extends beyond any single model. It’s embedded in the way MiniMax approaches its technology stack and operations.
How MiniMax broke free from big tech’s capital pull
A year ago, founders of foundation model startups shared the same anxiety: what happens when a tech giant enters your space?
Investors would get spooked. Partners get cautious. And the whole playing field tilts.
That fear wasn’t unfounded. Every major tech company, at home and abroad, had piled into the foundation model race. With so much competition, many predicted a repeat of past capital-heavy battles, like those seen in the bike sharing or food delivery sectors.
The rationale was simple. Foundation models require enormous computing power, vast datasets, and elite talent. These are all things big tech companies already command.
And yet, just one year later, the chaos has settled. Many challengers have exited. Today’s leaderboards are led not by legacy tech giants, but by newer entrants like OpenAI, Anthropic, DeepSeek, and arguably MiniMax.
Why? Because in this field, money only buys you a ticket to the race. Winning demands alpha: an edge that hasn’t yet been priced in. And startups, with speed and sharper instincts, often find that edge first.
MiniMax, for example, saw its Talkie app surpass ten million downloads in its first eight months last year, making it the fourth most downloaded AI-integrated app in the US, ahead of Character.AI. Financial Times pegged its 2024 revenue at around USD 70 million.
On the tech side, its M1 model has 456 billion parameters and ranks among the top two open-weight models globally, according to Artificial Analysis benchmarks. It supports one million tokens of context, which is eight times that of DeepSeek’s R1, and outputs up to 80,000 tokens, beating Gemini 2.5 Pro’s 64,000-token limit.
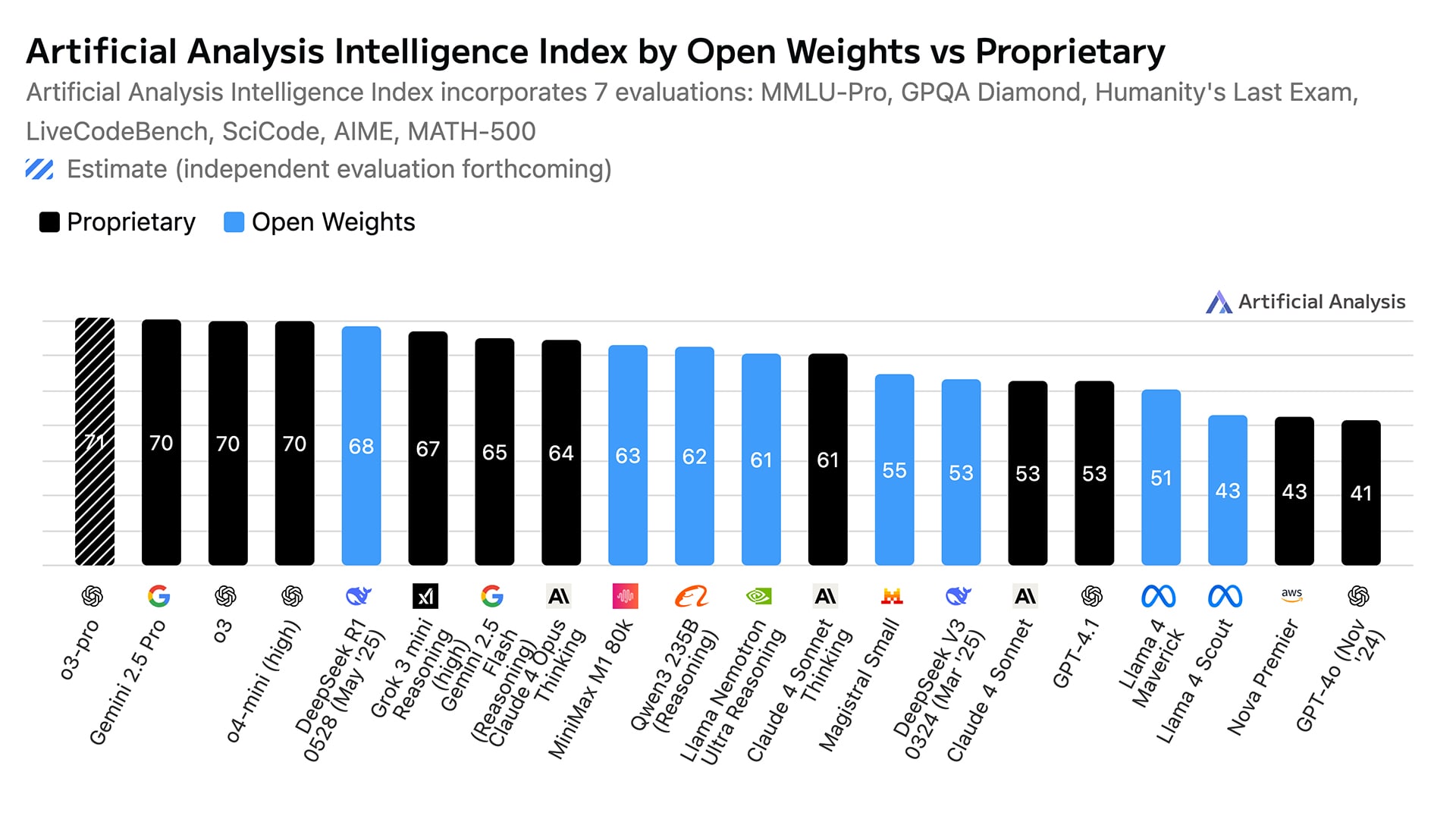
Why does that matter? Tasks like research or deep code reasoning require long context. In agent systems, sub-agent outputs must feed into a master agent. If the context window is too small, the process breaks down.
M1 also excels in tool use. On the Tau-Bench, MiniMax-M1-40K outperforms even closed models like Gemini 2.5 Pro. It maintains stability through more than 30 rounds of reasoning and tool use.
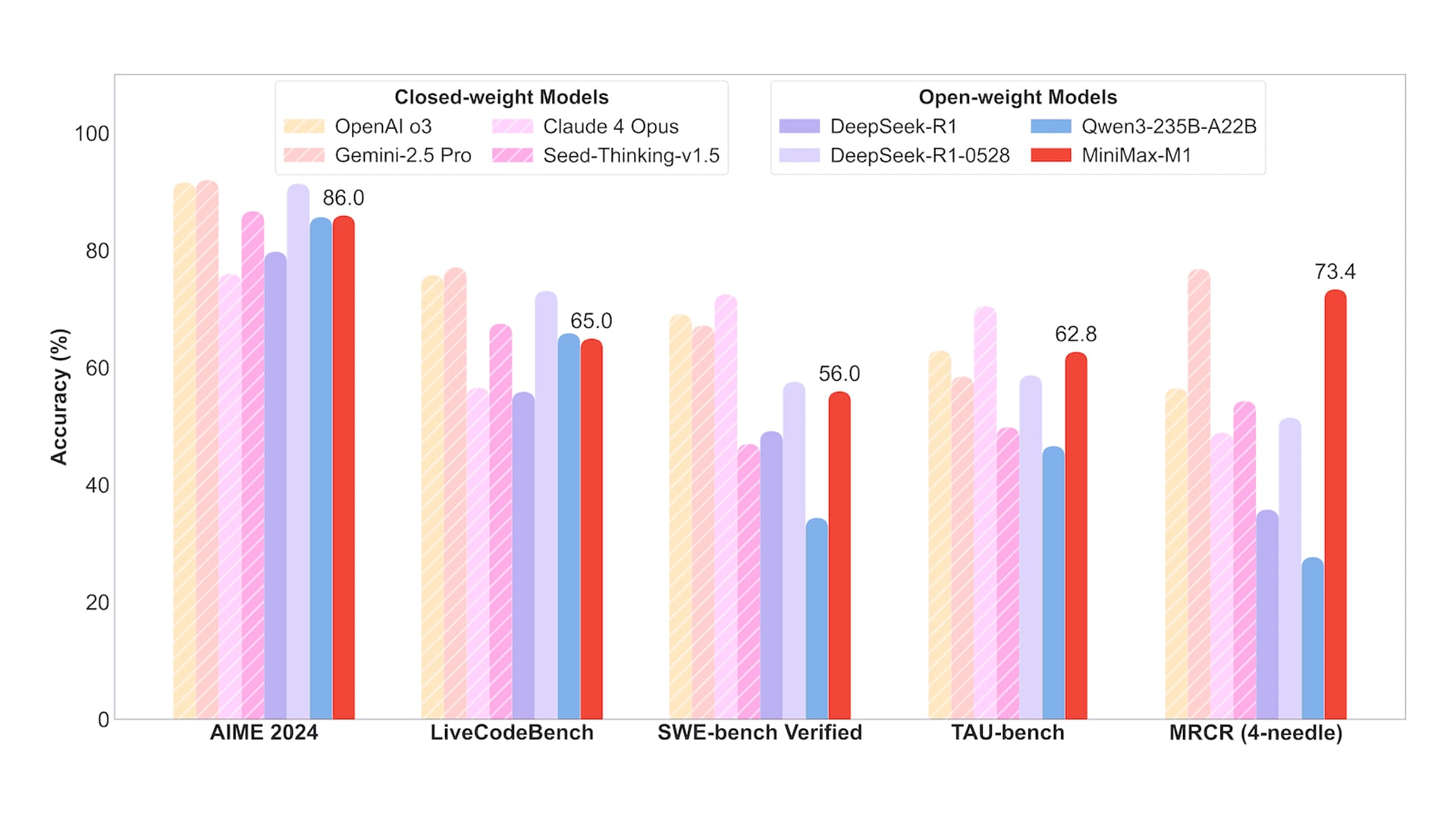
So where does this edge come from?
First: architecture. M1 builds on the MiniMax-Text-01 base model and leverages reinforcement learning and mixture-of-experts (MoE) technology. MiniMax was one of the first in China to embrace MoE in 2023, before it became standard practice.
It also developed early versions of hybrid attention mechanisms. M1 uses “lightning attention,” assigning one-eighth of the computation to standard self-attention, with the rest processed through a linear method. The input is divided into tiles, allowing local detail with global semantic coherence.
Second: training method. Rather than using PPO (proximal policy optimization) or GRPO (group relative policy optimization), MiniMax developed CISPO (clipped IS weight policy optimization), which weighs tokens based on semantic value.
Where PPO and GRPO often dilute the significance of rare but crucial tokens like “however,” “wait,” or “aha,” CISPO amplifies them. This improves not just output length but overall quality.
With CISPO, MiniMax completed reinforcement learning in three weeks using 512 H800 GPUs, at a cost of roughly USD 530,000. Compared with DAPO (decoupled clip and dynamic sampling policy optimization), it halved the training steps for the same results.
Inference costs are low as well. M1 uses just 25% of DeepSeek R1’s compute to produce 100,000 tokens, yet still performs better on math and coding tasks.
Yes, building foundation models is expensive. But once a company clears that initial hurdle, the real competition comes down to innovation: lowering cost, raising accessibility, and pushing performance limits.
How AI agents bridge innovation and application
Over the past decade, AI development has come in waves. The first, sparked by breakthroughs like AlexNet and AlphaGo, remained confined to computer vision and NLP (natural language processing). It eventually fizzled.
The second, powered by foundation models, has proven more durable due to its general-purpose utility and commercial potential.
In this wave, aha moments arrive in two forms. Some are breakthroughs in core models like ChatGPT or DeepSeek-R1. Others come from agent-based products such as Cursor, Lovart, and Manus.
Agents shine because they can string together multi-step processes into cohesive workflows. A strong demo can convert a technical prototype into a market-ready product. That’s what Hailuo Video Agent just demonstrated.
Hailuo’s tool differs from conventional video generators. It’s easier to use and more controllable, capable of producing complete clips in one go, whether of diving cats, spinning alpacas, or elaborate performances. It supports over 100 video templates, covering everything from art films and ads to music videos and meme formats.
This positions AI to manage the full creative pipeline: from concept and storyboarding, to generation, to post-production.
Users simply enter a prompt. The system handles the rest, with transparent reasoning paths similar to those in DeepSeek-R1’s early demonstrations.
Hailuo has led the video AI category globally for six consecutive months, outperforming Sora, Runway, and other international competitors.
RELATED ARTICLE

Then there’s MiniMax Agent, the company’s general-purpose AI system.
While Hailuo focuses on video, MiniMax Agent handles long-horizon, complex tasks. It can deconstruct goals, create expert-level plans, and execute multi-step operations. It’s widely used internally for tasks like coding, building websites, and making presentations.
It understands longform content across text, audio, image, and video. With its model context protocol (MCP) extensions, it supports animations, advertising content, and slide decks.
One demo showed it building an interactive web page about the Louvre Museum, complete with media and engagement features.
Beyond being a productivity tool, MiniMax Agent reflects the depth of MiniMax’s foundation model and multimodal system.
And why should companies building foundation models also build agents? Because they have control over model architecture and training loops. They can create feedback systems that refine performance and reduce costs.
Put simply, model innovation lifts the ceiling. Agents help define the next frontier. The two are interdependent.
MiniMax launched in early 2022, nearly a year before ChatGPT became a household name. Once public attention spiked, many began asking: who is MiniMax?
The answer: a company that has consistently followed its own path.
In 2023, while most of China’s AI market was fixated on dense models, MiniMax allocated more than 80% of its compute to MoE. In early 2024, it launched China’s first MoE-based foundation model.
In January, it open-sourced its lightning attention protocol, altering core transformer architecture in pursuit of new performance gains.
By June, its M1 model had reached second place in global open-source rankings, backed by architectural and algorithmic advances across the board.
Launched alongside it, the general-purpose MiniMax Agent addresses key challenges in AI agent deployment, including multimodality, long-horizon reasoning, task decomposition, and tool coordination.
MiniMax is a company that never seems to tire, that constantly reinvents itself, and that is always chasing the next performance ceiling.
At its core, this drive reflects a belief in the foundation model race’s endgame: that a great business starts with a simple idea, pursued through focused, uncompromising technical innovation.
KrASIA Connection features translated and adapted content that was originally published by 36Kr. This article was written by Xiao Xi for 36Kr.