Zhipu AI is putting its foot on the gas in the race for multimodal artificial intelligence supremacy. On July 26, 2024, it launched Zhipu Qingying, a video generation model akin to Sora. While Sora remains inaccessible months after its release, Qingying was made available to the public for free from day one.
A month later, on August 29, Zhipu made a splash at the International Conference on Knowledge Discovery and Data Mining (KDD), debuting “Her,” a GPT-4o-like model. This was featured in the consumer-facing product Zhipu Qingyan, which introduced a new “video call” function—bringing AI one step closer to human-like communication.
Qingyan stays updated on trends, too. After checking out the viral game Black Myth: Wukong, it quickly understood the content and could chat with users about it.
Alongside these updates, Zhipu rolled out a new multimodal model suite, featuring the visual model GLM-4V-Plus, which can understand both videos and web pages, and the text-to-image model CogView-3-Plus.
The base language model GLM has also been upgraded to GLM-4-Plus, a model capable of handling long texts and solving complex math problems with ease.
GPT-4o: Homework helper, tutor, and kitchen assistant
Previously, GPT-4o wowed users with its emotion-predicting abilities. But Qingyan takes a more straightforward approach, reminding users that, as an AI, it can’t express emotions.
That said, Qingyan’s video call feature opens up practical applications tailored to China’s focus on lifelong learning.
For example, it can serve as a personal English tutor. With the camera on, users can learn on demand, anytime, anywhere. Qingyan also doubles as a math teacher—its explanations rival those of real-life tutors. Parents can finally take a breather from homework stress.
At home, Qingyan acts as a personal assistant, too. It can recognize a Luckin Coffee bag and provide a brief history of the brand. Though sometimes, it veers off course—like when it explained how to store the bag instead of the coffee inside.
Though video call histories can’t be saved yet, using Qingyan feels like having a tutor, homework helper, and kitchen assistant rolled into one.
New visual model: From video understanding to code interpretation
At KDD, Zhipu AI unveiled its updated model suite, including a new generation of its base language model and an enhanced multimodal family: GLM-4V-Plus and CogView-3-Plus.
What’s notable about GLM-4-Plus is that it was trained using high-quality synthetic data. This has proven that AI-generated data can be highly effective for model training, reducing costs. According to Zhipu AI, GLM-4-Plus’s language understanding rivals GPT-4o and Llama 3.1-405B.
| Model | AlignBench | MMLU | MATH | GPQA | LCB | NCB | IFEval |
|---|---|---|---|---|---|---|---|
| Claude 3.5 Sonnet | 80.7 | 88.3 | 71.1 | 56.4 | 49.8 | 53.1 | 80.6 |
| Llama 3.1 405B | 60.7 | 88.6 | 73.8 | 50.1 | 39.4 | 50 | 83.9 |
| Gemini 1.5 Pro | 74.7 | 85.9 | 67.7 | 46.2 | 33.6 | 42.3 | 74.4 |
| GPT-4o | 83.8 | 88.7 | 76.6 | 51.0 | 45.5 | 52.3 | 81.9 |
| GLM-4-Plus | 83.2 | 86.8 | 74.2 | 50.7 | 45.8 | 50.4 | 79.5 |
| GLM-4-Plus/GPT-4o | 99% | 98% | 97% | 99% | 101% | 96% | 97% |
| GLM-4-Plus/Claude 3.5 Sonnet | 103% | 98% | 104% | 85% | 92% | 95% | 99% |
In terms of long-text capabilities, GLM-4-Plus performs on par with GPT-4o and Claude 3.5 Sonnet. On the InfiniteBench test suite, created by Liu Zhiyuan’s team at Tsinghua University, GLM-4-Plus even slightly outperformed these leading models.
| Model | LongBench-Chat | InfiniteBench/EN.MC | Ruler |
|---|---|---|---|
| Mistral-123B | 8.2 | 38.9 | 80.5 |
| Llama 405B | 8.6 | 83.4 | 91.5 |
| Claude Sonnet 3.5 | 8.6 | 79.5 | – |
| Gemini 1.5 Pro | 8.6 | 80.9 | 95.8 |
| GPT-4o | 9.0 | 82.5 | – |
| GLM-4-Plus | 8.8 | 85.1 | 93.0 |
| GLM-4-Plus/GPT-4o | 98% | 103% | – |
| GLM-4-Plus/Claude 3.5 Sonnet | 102% | 107% | – |
Moreover, by adopting proximal policy optimization (PPO)—a method that enhances decision-making in complex tasks—GLM-4-Plus has significantly boosted its data and code inference abilities and better aligns with human preferences.
The processing cost for 1 million tokens with GLM-4-Plus is RMB 50 (USD 7), comparable to Baidu’s latest large model, Ernie 4.0 Turbo, which costs RMB 30 (USD 4.2) for input and RMB 60 (USD 8.4) for output per million tokens.
But what’s truly groundbreaking is its multimodal capability.
| Model | OCRBench | MME | MMStar | MMVet | MMMU-Val | AI2D | SEEDBench-IMG |
|---|---|---|---|---|---|---|---|
| Claude 3.5 Sonnet | 788 | 1920 | 78.5 | 62.2 | 66.0 | 80.2 | 72.2 |
| Gemini 1.5 Pro | 754 | 2110.6 | 73.9 | 59.1 | 64.0 | 79.1 | – |
| GPT-4V-1106 | 516 | 1771.5 | 73.8 | 49.7 | 63.6 | 75.9 | 72.3 |
| GPT-4V-0409 | 656 | 2070.2 | 79.8 | 56.0 | 67.5 | 78.6 | 73.0 |
| GPT-4o | 736 | 2310.3 | 80.5 | 69.1 | 69.2 | 84.6 | 77.1 |
| GLM-4V-Plus | 833 | 2274.7 | 82.4 | 69.9 | 53.3 | 83.6 | 77.4 |
| GLM-4-Plus/GPT-4o | 113% | 99% | 102% | 101% | 99% | 99% | 100% |
| GLM-4-Plus/Claude 3.5 Sonnet | 106% | 118% | 105% | 106% | 81% | 104% | 107% |
GLM-4V-Plus, the new visual model, now understands videos and web pages—significant improvements over its predecessor.
For instance, uploading a screenshot of Zhipu AI’s homepage allows GLM-4V-Plus to instantly convert it into HTML code, helping users quickly recreate a website.
Unlike typical video comprehension models, GLM-4V-Plus not only understands complex videos but also has a sense of time. You can ask it about specific moments in a video, and it can identify the exact content. However, as of this writing, Zhipu AI’s open platform doesn’t yet support video uploads for this feature.
Despite its impressive visual capabilities, GLM-4V-Plus lags in multi-turn dialogues and text understanding, meaning it’s not yet on par with GPT-4o in this regard.
| Model | MVBench | LVBench | Temporal QA | Multi-turn Dialogue | Chinese-English Support |
|---|---|---|---|---|---|
| LLaVA-NeXT-Video | 50.6 | 32.2 | ❌ | ❌ | ❌ |
| PLLaVA | 58.1 | 26.1 | ❌ | ❌ | ❌ |
| LLaVA-OneVision | 59.4 | 27.0 | ❌ | ✅️ | ✅️ |
| GPT-4o | 47.8 | 34.7 | ❌ | ✅ | ✅️ |
| Gemini 1.5 Pro | 52.6 | 33.1 | ✅️ | ✅️ | ✅️ |
| GLM-4V-Plus | 71.2 | 38.3 | ✅️ | ✅️ | ✅️ |
| GLM-4-Plus/GPT-4o | 149% | 110% | – | – | – |
| GLM-4-Plus/Gemini 1.5 Pro | 135% | 116% | – | – | – |
At KDD, Zhipu AI also introduced CogView-3-Plus, the next generation of its text-to-image model. Compared to FLUX, the current frontrunner in the field, CogView-3-Plus holds its own in generating images within 20 seconds.
| Model | Clip Score | AES Score | HPSV2 | ImageReward | PickScore | MPS |
|---|---|---|---|---|---|---|
| SD3-Medium | 0.2655 | 5.52 | 0.2774 | 0.2144 | 21.31 | 10.57 |
| Kolors | 0.2726 | 6.14 | 0.2833 | 0.5482 | 22.14 | 11.86 |
| DALLE-3 | 0.3237 | 5.95 | 0.2904 | 0.9734 | 22.51 | 11.95 |
| MidJourney-V5.2 | 0.3144 | 6.12 | 0.2813 | 0.8169 | 22.74 | 12.40 |
| MidJourney-V6 | 0.3276 | 5.95 | 0.2798 | 0.8351 | 22.78 | 12.34 |
| Flux-dev | 0.3155 | 6.04 | 0.2881 | 1.0333 | 22.96 | 10.12 |
| CogView-3-Plus Full (20s) | 0.3177 | 5.90 | 0.2963 | 0.9797 | 22.53 | 12.55 |
| CogView-3-Plus Lite (5s) | 0.3119 | 5.91 | 0.2843 | 0.9384 | 22.52 | 12.48 |
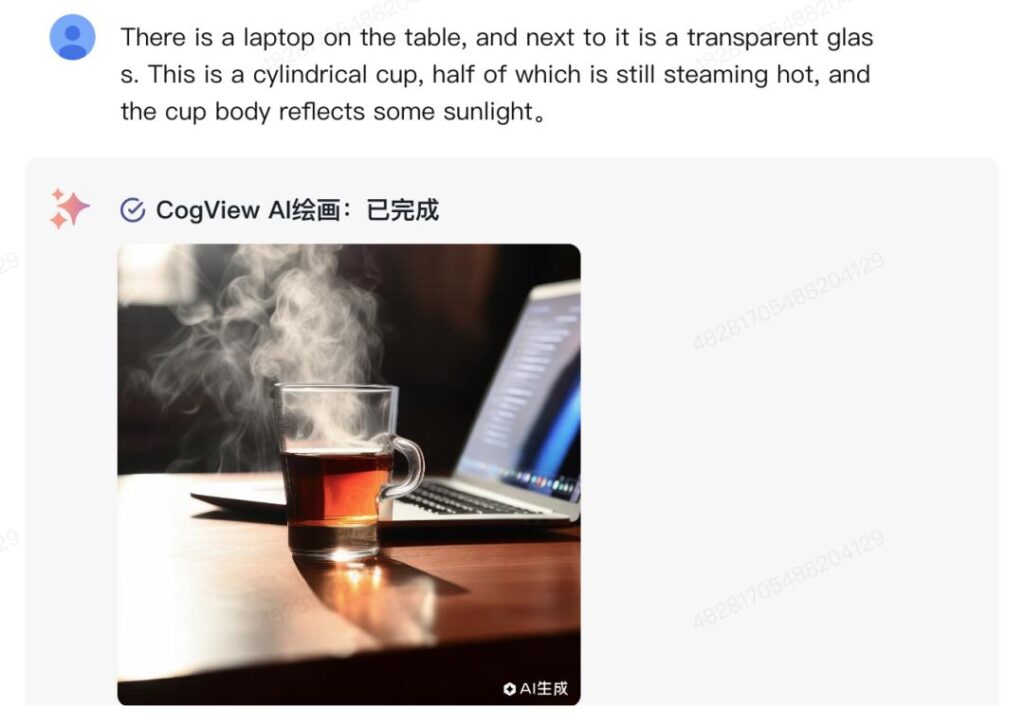
CogView-3-Plus also supports image editing, such as changing object colors or replacing items in an image.

It took Zhipu AI over seven months to add the “Plus” suffix to models launched in January 2024—its longest development cycle since 2023.
What’s clear is that GPT-4o represents a pivotal moment for AI companies. As multimodal capabilities merge, the “black box” of language understanding is beginning to open—only to be quickly resealed by GPT-4o.
Most Chinese AI companies are adopting a divide-and-conquer strategy, first enhancing single-modal capabilities before tackling integration challenges. Zhipu AI is still in this phase, but the launch of its video call feature hints at the early stages of multimodal fusion.
KrASIA Connection features translated and adapted content that was originally published by 36Kr. This article was written by Zhou Xinyu for 36Kr.